오늘은 웹 크롤링에 대해 알아보는 시간을 가졌습니다.
웹 크롤링에 대한 경험이 있지만 독학으로 완벽하게 알지 못하므로 도움이 될 것이라고 생각했습니다.
회로망
네이버 뉴스 기사를 예로 들어보겠습니다.
http://news.naver.com:80/main/read.nhn?mode=LSD&mid=shm&sid1=105&oid=001&aid=0009847211#da_727145
- https:// → 프로토콜
- 메시지 → 하위 도메인
- naver.com → 도메인
- 80 → 포트
- /main/ → 경로
- read.nhn → 페이지
- ?mode=LSD&mid=shm&sid1=105&oid=001&aid=0009847211 → 쿼리
- #da_727145 → 파편
데이터를 요청하는 방법에는 두 가지가 있습니다.
1. 접수: 데이터는 URL에 포함되며 길이가 제한됩니다.
2번째 포스트: 본문에 데이터가 포함되어 있으므로 데이터가 숨겨집니다.
페이지 유형
1. 정적 페이지: 한번 화면이 표시되면 이벤트에 의한 화면전환은 없습니다.
2. 동적 페이지: 화면이 표시된 후 서버에서 데이터를 가져와 이벤트가 발생하고 화면이 변경됩니다.
웹 페이지의 유형과 검색할 데이터의 특성에 따라 얻을 수 있는 다양한 웹 크롤링 방법이 있습니다.
웹을 크롤링하는 4가지 방법
1. json 요청
: JSON 문자열로 구문 분석(주로 동적 페이지)

import requests
url = "크롤링 하고자 하는 링크"
## 1. json 데이터 가져오기
response = requests.get(url)
response # 200이 아닌 403, 500과 같은 code가 나온다면 수집이 제대로 안된것이다.
# 가져온 문자열을 확실하게 확인하는 방법
response.text## 2. json을 DF로 변경
data = response.json() # list로 변경
df = pd.Datarame(data) # df로 변경
위의 프로세스는 원하는 페이지를 가져오는 기능으로 전환될 수 있습니다. B. 페이지 크기 및 페이지 크기.
import requests
def crawling(page, page_size):
url = f"크롤링 하고자 하는 링크" # page, page_size에 해당하는 부분을 f-string
## 1. json 데이터 가져오기
response = requests.get(url)
## 2. json을 DF로 변경
data = response.json() # list로 변경
df = pd.Datarame(data) # df로 변경
return df
단, 위와 같이 했을 때 응답코드가 200이 아닌 403이면 서버에서 차단한 것입니다.
사용자 에이전트와 리퍼러를 변경하여 이 문제를 해결할 수 있는 방법이 있습니다.
User-Agent 및 Referer는 F12를 누른 후 네트워크 탭에서 찾을 수 있습니다. 아마도 업데이트 후 첫 번째 일 것입니다.
(리퍼러는 내가 크롤링하고 싶은 사이트로 가기 직전의 사이트)
import requests
def crawling(page, page_size):
url = f"크롤링 하고자 하는 링크"
## user agent, referer 변경
headers = {
'user-agent' : '복사한 user-agent',
'referer' : '복사한 referer'
}
# requests.get의 headers 속성에 적용
response = requests.get(url, headers=headers)
data = response.json()
df = pd.Datarame(data)
return df위의 방법으로도 200이 나오지 않는다면 다른 방법으로 악용을 방지하고 있기 때문에 다른 방법을 찾아야 합니다.
2.요청 API
API를 가져오는 대표적인 방법은 파파고 번역 서비스입니다.
이러한 API를 노출하는 서비스는 애플리케이션을 등록하고 서비스 인증 키를 얻은 후에만 사용할 수 있습니다.
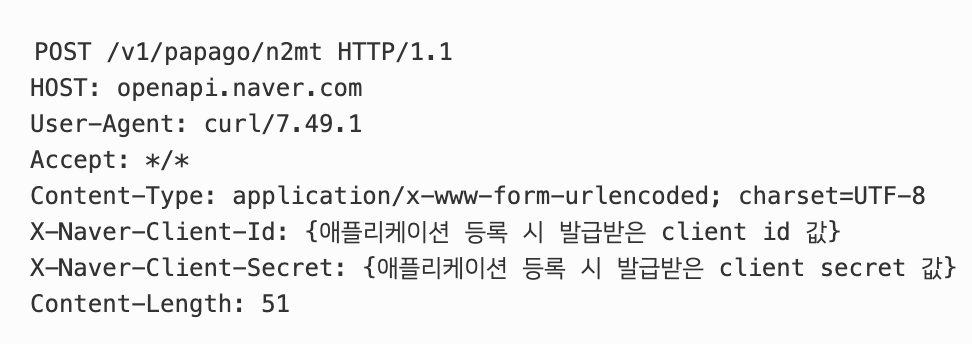
이러한 API 서비스의 대부분은 이를 따를 수 있도록 사용 방법에 대한 지침을 제공합니다.
## 1. API
ko_txt="번역하고자 하는 문장"
url="https://openapi.naver.com/v1/papago/n2mt"
headers = {
'Content-Type' : 'application/json',
'X-Naver-Client-Id' : '발급받은 ID 값',
'X-Naver-Client-Secret' : '발급받은 시크릿 값',
}
params = {
'source': '번역하고자 하는 문장의 언어코드',
'target': '목적 언어의 언어코드',
'text': ko_txt}
## 2. 불러오기
response = requests.post(url, json.dumps(params), headers=headers)
# 여기서 json.dumps(params)는 한글을 인코딩하는 과정이다.(안하면 에러)
## 3. 번역 결과
response.json()('message')('result')('translatedText')
# response.json()를 출력하면 내가 원하는 값이 어디있는지 알 수 있다.
# 이를 통해 key값을 불러와서 내가 원하는 value 값을 가져오면 완성이다.
3. HTML 요청
: HTML 문자열에서 구문 분석(대부분 정적 페이지)
from bs4 import BeautifulSoup
import requests
url="크롤링 하고자 하는 페이지"
## 1. html로 데이터 가져오기
response = requests.get(url)
dom = BeautifulSoup(response.text, 'html.parser')
## 2. 특정 부분을 css selector를 통해 불러오기
elements = dom.select('복사한 css selector')
## 3. DF로 변환
data = ()
for element in elements: # 1개씩 접근
data.append({
'title' : element.select_one('.itemname').text,
'link' : element.select_one('.itemname').get('href'),
'image' : 'https:' + element.select_one('img').get('data-original'),
# src에 있긴 하지만, 이거는 앞부분만 뜨고 뒷부분은 비어있다.
# 스크롤을 해야 src에 있는 링크가 보인다. 따라서 data-original에 들어있는 링크로 들어가야 잘 보인다.
# 나중에 크롤링을 할 때 이런 것도 확인을 해보길 바란다.
'o_price' : element.select_one('.o-price').text,
's_price' : element.select_one('.s-price').text.strip().split('\n')(0),
})
df = pd.DataFrame(data)
## 4. img 링크를 이용하여 이미지 다운
img_link = df.loc(0, 'image') # 첫 번째 상품의 이미지
response = requests.get(img_link) # 이미지를 받아오기
with open('저장할 경로', 'wb') as file: # write binary 이진형태로
file.write(response.content)
4. 셀레늄
: 브라우저를 직접 열어 데이터 가져오기
Selenium은 Chrome 브라우저 드라이버를 사용하여 Python으로 브라우저를 제어하는 크롤링 방식입니다.
웹 크롤링이 처음이라면 셀레늄이 매우 생소할 수 있습니다. 크롤링을 처음 공부했을 때 셀레늄이 너무 신기했던 것 같아요.
먼저 Chrome 드라이버를 다운로드하고 압축을 풉니다.
다음으로 Windows의 경우 현재 Jupyter 노트북과 동일한 위치에 chromedriver.exe 파일을 배치해야 합니다.
Mac은 Windows, Linux 명령어와 동일하게 실행 가능 sudo cp ~/Download/chromedirver /usr/local/bin으로 구성하는 방법도 있습니다.
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('크롤링 하고자 하는 사이트')
# F12를 눌러서 작용하려는 위치의 css_selector를 복사
driver.find_element(By.CSS_SELECTOR, '#q').send_keys('파이썬') # 파이썬 검색
driver.find_element(By.CSS_SELECTOR, '.inner_search > .ico_pctop.btn_search').click() # 클릭
# 자바스크립트 코드 실행 이용하여 스크롤 내리기
driver.execute_script('window.scrollTo(200, 300);')
# 크롬창 닫기
driver.quit()
웹크롤링은 독학으로 구글링하다 접해서 체계적으로(?) 진행되지는 않았지만 이번 강의를 통해 웹크롤링이 어느 정도 정리가 된 것 같아서 좋았습니다!!